This document written: 2023-09-20
Kotlin の Coroutine について、やっと理解が整理できてきたので、まとめておきたいと思う。
まず、Google 公式のガイドとしては、「Android での Kotlin コルーチン」があるが、これだけでは一体何が言いたいのかイマイチ要領を得ない文書である。原語の英語版である “Kotlin coroutines on Android” の方が却って良くわかる。我々日本語ネイティヴにとっては、英語版は読むのに時間がかかり翻訳版の方がざっと全体に目を通すには都合が良いが、一方で翻訳版は日本語としてはすんなり読めても、文書として結局何を言いたいのかがよくわからなかったりする。これはおそらく、Google の文書が技術者が翻訳したものではなく、文系出身の非技術者が翻訳したものなので、結局実際のことは何もわかっていない人間が言語だけ日本語の文章に直してできあがったものだからだろう。
まあ、その言語の壁を越えて、原語の英語版で読み込んだとしても、依然として、Google の文書には問題がある。技術者の独り善がりな文書になっていて、物凄く不親切である。
Coroutine そのものとは関係ない情報が混ぜこぜになっており、本来の Coroutine についての説明が、読者から見えにくくなっている。基本的に、サンプルが、「ネットワーク上にある Repository に、JSON をポストしてログインする」というシステムであるという状況設定であること。そのこと自体が把握しにくい。まずはこの文書のサンプルがそのような状況設定であることを把握した上で、「ネットワーク上にある Repository に、JSON をポストしてログインする」という処理の内容についても、理解が追い付ける人でなければ、Coroutine 自体の説明として理解することが難しくなっている。
わざわざ「JSON をポストしてログインする」ということをせずとも、普通に、Web で HTTP GET するだけの状況設定でも良かったはずである。説明の焦点は Coroutine にあるのだから。さらに、ViewModel を使って、MVVM モデルを絡めたりと、この文書を書いた Google の技術者は何をカッコつけたがっているのだろうか? 読者の読解のハードルを上げているだけなのに。
この文書のサンプルでは、結局のところ、2 つのコードブロックについて説明している。1 つ目はネットワークログイン処理をする LoginRepository クラスの makeLoginRequest 関数であり、
// Function that makes the network request, blocking the current thread
fun makeLoginRequest(
jsonBody: String
): Result<LoginResponse> {
val url = URL(loginUrl)
(url.openConnection() as? HttpURLConnection)?.run {
requestMethod = "POST"
setRequestProperty("Content-Type", "application/json; utf-8")
setRequestProperty("Accept", "application/json")
doOutput = true
outputStream.write(jsonBody.toByteArray())
return Result.Success(responseParser.parse(inputStream))
}
return Result.Error(Exception("Cannot open HttpURLConnection"))
}
もう 1 つは、その関数を利用する側(login 関数ブロック内)である。
loginRepository.makeLoginRequest(jsonBody)
要するに、
この 2 つについて「Coroutine を適用すると、コードがどう変っていくか」を説明しているに過ぎないのである(そう考えると、当該文書が、いかに邪魔な情報が多い悪文であるかがわかるだろう)。
そして、上のことがわかって当該文書を読み解けば、
suspend fun makeLoginRequest(
jsonBody: String
): Result<LoginResponse> {
return withContext(Dispatchers.IO) {
// Blocking network request code
}
}
// Create a new coroutine on the UI thread
viewModelScope.launch {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
// Make the network call and suspend execution until it finishes
val result = loginRepository.makeLoginRequest(jsonBody)
// Display result of the network request to the user
when (result) {
is Result.Success<LoginResponse> -> // Happy path
else -> // Show error in UI
}
}coroutineScope は、サンプルでは viewModelScope を使っているが、もちろん、ViewModel を使わない場合、例えば通常の Activity では、lifecycle.coroutineScope を使ったりする(この点も、当該文書が不親切な点である)。この coroutineScope というのは、元々は Kotlin の言語処理系で用意されているものだが、Android プログラミングでは、システム(Android OS)側で用意されているものを使うことになる。Lifecycle に応じて coroutine を自動でキャンセル処理などをするための、そのスコープ(範囲)を設定するためのものである。
同じこと(Android システム側の用意したものを選んで使う)は、Dispatchers についても言えるが、とりあえずネットワーク処理については、Dispatchers.IO を使えばよい。
当該文書で解説しているのは、要するに、上の 2 つについてである。さらにオマケとして、例外処理 try-catch の使用例を付け加えて、文書が終っている。
viewModelScope.launch {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
val result = try {
loginRepository.makeLoginRequest(jsonBody)
} catch(e: Exception) {
Result.Error(Exception("Network request failed"))
}
when (result) {
is Result.Success<LoginResponse> -> // Happy path
else -> // Show error in UI
}
}
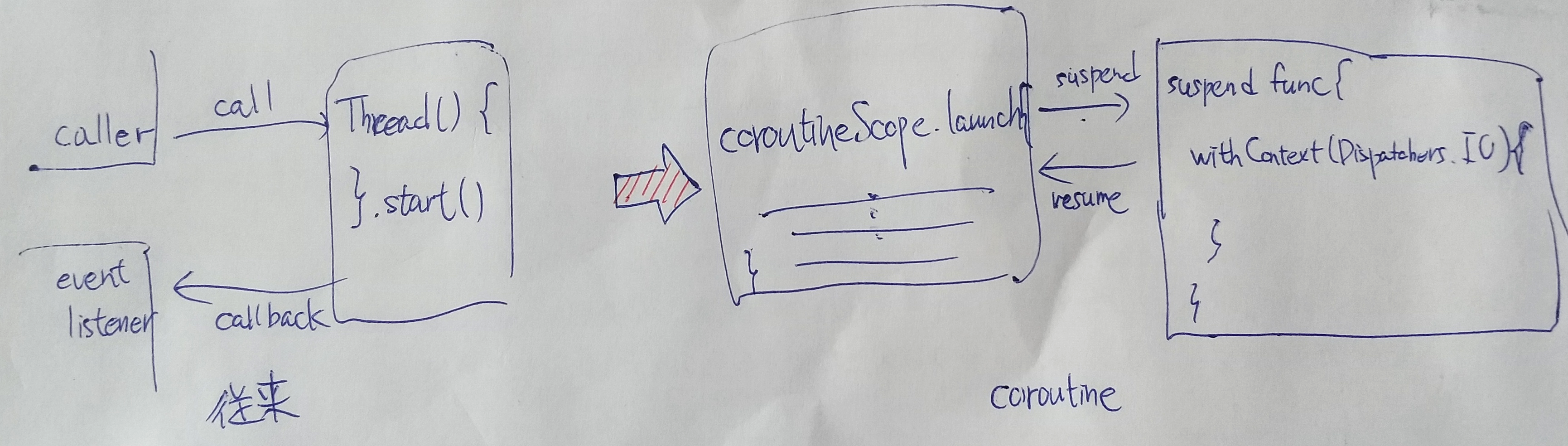
一旦、Java で確立された Thread 間通信の記述方法である、イベントリスナー&コールバックを習得してしまうと、なぜ今さら Coroutine が必要なのかと思ってしまう。さらに、そのイベントリスナー&コールバックの慣行から考えようとして、却って Coroutine の理解がイマイチし辛くなってしまう。
Kotlin が実際に、Java VM を使ってどのような処理に変換して、Coroutine を実装しているのか、そこまで深掘りして調べたわけではないので、技術的根拠があるのではないが、あくまでもエンド・プログラマーの立場でプログラミングをする時の視点で述べると、Java のイベントリスナー&コールバックの、呼出元(caller)とイベントリスナーをシームレスに記述できるようにしたのが、Coroutine と考えればいいのではないのかと思っている。
つまり、Java でネットワーク等の何らかの非同期な処理を行う関数を呼び出す場合、呼出元では、呼び出す処理を記述する。そして呼び出された非同期処理が終った時、処理を呼出元に戻すが、この場合、イベントリスナーに戻った後の処理を記述する。つまり、呼び出す処理と、戻ってきた後の処理が、記述される場所がバラバラのメソッドのブロックに存在することになる。
これが、コードの可読性を悪くするのみならず、ライフサイクル的にも、インスタンスの破棄時に、イベントリスナーを取り消す処理を適切に用意する必要があったり、「コールバック地獄」など呼ばれたりして、悩みの種であった。
Coroutine の場合、呼び出す処理と、戻ってきた後の処理が、suspend / resume 機構によって、そのままシームレスに一連の記述としてコーディングすることができ、可読性が非常に良く、さらに、coroutineScope によって、ライフサイクルを考慮したクリアランス処理が Kotlin の言語の仕組みとして暗黙的に行われる。
一旦、わかってしまえば、プログラマー視点としては、Coroutine の方が自然であり、一方、イベントリスナー&コールバックの記法はプログラマー側が言語処理系側に無理して視点を合わせていたのだということがわかる。
つまり、どちらかというと、世間でよく表現されているように、「Coroutine と Thread を比較する」という観点でものを語るというよりは、「Coroutine と Event listener & Callback を比較する」という観点で語るべきではないかと思う。Coroutine でもおそらくは、Dispatchers を使って、別 Thread を使った処理を行う場合もあるから、Coroutine と Thread 自体を対立させて語るのは本当は間違っていて、混乱の元ではないかと思う。
要するに、従来の Java では、Caller --call-> Thread --callback-> Event Listener だったのが、Thread 化する部分は withContext(Dispatchers.IO) を suspend 関数内で行い、その suspend 関数を call/listen する部分(Caller + Event Listner に相当する部分)は一続きに統合して、coroutineScope 内で行って、クリアランス範囲を明確にする。
<Android>